

在最近的一篇博客文章中,我们讨论了如何在 COMSOL Multiphysics® 中使用“域分解”求解器来计算大型问题,并介绍了集群上的并行计算。文章还展示了多种节省内存的途径,主要包括在集群上对自由度进行空间分解和在单节点计算机上启用重新计算并清除 选项。为了进一步说明“域分解”求解器在减少内存占用方面的优势,让我们来具体探讨一个热粘性声学问题:模拟穿孔板的转移阻抗。
热粘性声学案例:穿孔板的转移阻抗
“域分解”求解器十分适合处理计算量很大的问题,因为它可以将问题的空间域划分为很多子域,然后依照顺序同时动态计算出子域结果,从而显著地提高了计算效率。我们已经了解如何将“域分解”求解器用作迭代求解器的预处理器,并讨论了在可用内存不足的情况下执行仿真的可能性。今天,我们将借助一个热粘性声学案例来详细介绍如何使用这一功能。
首先,让我们来介绍穿孔板的转移阻抗教学模型,您可以前往“案例下载”页面,在“声学模块”分类中找到它。此案例模型使用了热粘性声学,频域 接口对一种带小孔的板材进行模拟,这种板材便是穿孔板。

穿孔板转移阻抗的仿真模型。
这个仿真案例十分复杂,我们需要求解穿孔板模型中转移阻抗的速度、温度与总声压。下面,让我们一起探讨当模型要求的解析度超出可用内存容量时,如何使用“域分解”求解器来计算上述物理量。
在 COMSOL Multiphysics® 中设置域分解求解器
让我们首先详细探讨一下如何针对穿孔板模型来设置“域分解”求解器。原始模型同时使用了全耦合式求解器与 GMRES 迭代求解器,并选用了两个混合直接预处理器作为模型的预处理器。预处理器的作用是将温度同速度和压力分离出来。默认情况下,混合直接预处理器和 PARDISO 是配合使用的。
随着网格解析度的逐渐提升,内存占用量也会持续增加。粘性边界层的最小厚度 dvisc 是模型中的一个重要参数,通常为 50 μm。穿孔板的厚度为几毫米,网格单元的最小单元尺寸设置为 dvisc/2。为了获得更为精细的解,我们用 dvisc 除以细化因子 r = 1,2,3,5。右键单击迭代 节点并选择域分解,即可插入域分解预处理器。在域分解 节点下,我们可以看到粗化求解器 与域求解器 节点。
为提升收敛速度,我们需要使用粗化求解器,但同时不希望添加额外的粗化网格。针对这一需求,我们可以使用代数粗化格点修正,具体操作是将粗化级别 > 使用粗化级别 设置为代数。在域求解器 节点下,我们添加了两个直接预处理器,并启用了混合设置,该设置与在原始模型中的用法相同。对于粗化求解器,我们则选用直接求解器 PARDISO。如果使用的是几何 粗化网格格点校正,我们也可以应用混合直接粗化求解器。
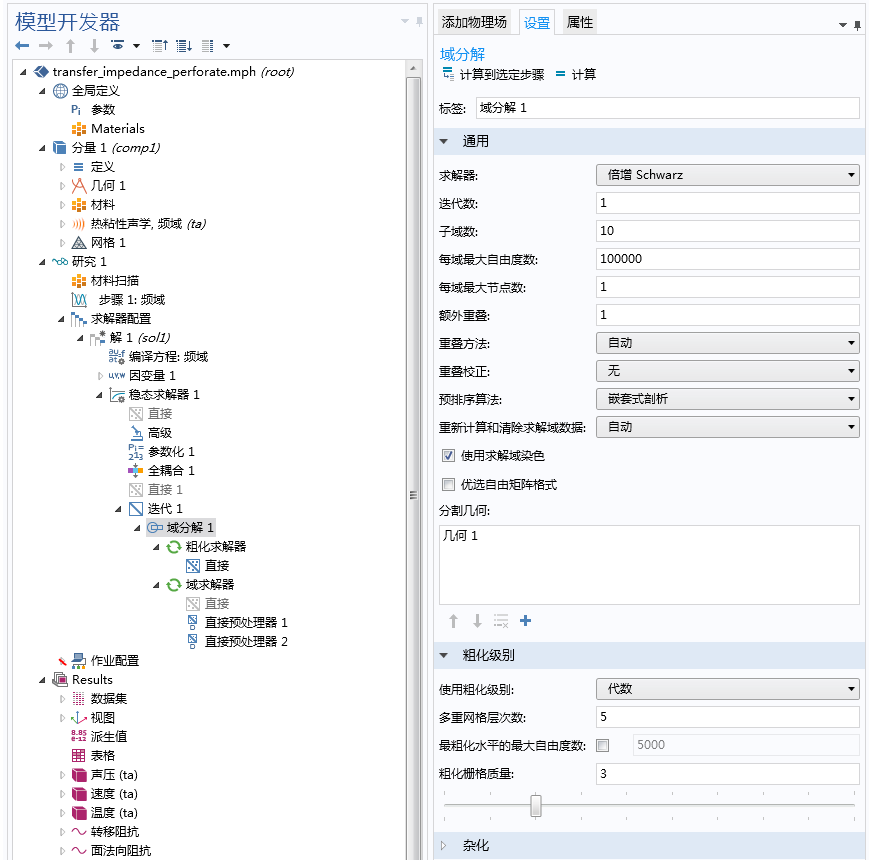
“域分解”求解器的设置。
比较三种求解器的资源消耗情况
下面,我们将对三种求解器的内存占用量进行比较,这三种求解器分布为带混合直接预处理功能的默认迭代求解器、直接求解器,以及单个工作站上、带域分解预处理功能的迭代求解器。针对细化因子 r = 1 的未细化网格,我们使用了 158,682 个自由度。三种求解器都占用了大约 5~6 GB 的内存来获取单频的值。r = 2 时自由度为 407,508 个,r = 3 时自由度为 812,238 个,这两种情况下,相比于其他两种迭代求解器,直接求解器占用了更多内存:当 r = 2 时,其内存占用量为 12~14 GB;当 r = 3时,其内存占用量为 24~29 GB。当 r = 5 且自由度为 2,109,250 个时,直接求解器的内存占用量为 96 GB,而时序机上的迭代求解器则占用了大约 80 GB 的内存。
“域分解”求解器的重新计算并清除 选项能够大幅减小总内存占用量,具体内容我们将在下文中进行探讨。
| 内存占用量,非分布式情况 | 自由度 | 内存占用量,直接求解器 | 内存占用量,带混合直接预处理功能的迭代求解器 | 内存占用量,带域分解预处理功能的迭代求解器 | 内存占用量,启用了“重新计算并清除”选项、带域分解预处理功能的迭代求解器 |
|---|---|---|---|---|---|
| 细化因子 r = 1 | 158,682 | 5.8 GB | 5.3 GB | 5.4 GB | 3.6 GB |
| 细化因子 r = 2 | 407,508 | 14 GB | 12 GB | 13 GB | 5.5 GB |
| 细化因子 r = 3 | 812,238 | 29 GB | 24 GB | 26 GB | 6.4 GB |
| 细化因子 r = 5 | 2,109,250 | 96 GB | 79 GB | 82 GB | 12 GB |
非分布式情况下,直接求解器和两种迭代求解器的内存占用量。
集群上每个节点的内存负载比单节点计算机要小很多。下面我们来看看细化因子 r = 5 时的模型。根据节点数量的不同,直接求解器能够对内存进行合理分配,当节点数量为 2个 和 4 个时,每个节点占用的内存分别为 65 GB 和 35 GB。在有 4 个节点的集群上,带域分解预处理功能的迭代求解器划分了 4 个子域,其中每个节点的内存占用量仅仅约为 24 GB。
| 集群上每个节点的内存占用量 | 内存占用量,直接求解器 | 内存占用量,带混合直接预处理功能的迭代求解器 | 内存占用量,带域分解预处理功能的迭代求解器 |
|---|---|---|---|
| 1 个节点 | 96 GB | 79 GB | 82 GB(2 个子域) |
| 2个节点 | 65 GB | 56 GB | 47 GB(2 个子域) |
| 4个节点 | 35 GB | 35 GB | 24 GB(4 个子域) |
当细化因子 r = 5 时,集群上直接求解器和两种迭代求解器中每个节点的内存占用量。
在单节点计算机中,“域分解”求解器的重新计算并清除 选项能够帮我们实现减少内存占用量的目标。然而,附加的代价是降低了计算性能。当 r = 5 时,2 个子域的内存占用量大约为 41 GB;4 个子域为 25 GB;22 个子域(默认设置可创建 22 个子域)为 12 GB。当 r = 3 时,2 个子域的内存占用量大约为 15 GB;4 个子域为 10 GB;8 个子域(默认设置)为 6 GB。
即使在单节点计算机中,域分解求解器的重新计算并清除 选项也能比直接求解器占用更少的内存:当细化因子 r = 5 时,前者的内存占用量约为 12 GB,而后者为 96 GB;当细化因子 r = 3 时,前者的占用量约为 6 GB,而后者为 30 GB。综上所述,尽管启用了重新计算并清除 选项的域分解求解器会降低计算性能,但是当内存不足时,它仍然是直接求解器中核外选项的一个可靠替代方案。
| 细化因子 | r = 3 | r = 5 |
|---|---|---|
| 内存占用量 | 30 GB | 96 GB |
当细化因子 r = 3 和 r = 5 时,单节点计算机上直接求解器的内存占用量。
| 子域数量 | 重新计算并清除 选项 | 细化因子 r = 3 | 细化因子 r = 5 |
|---|---|---|---|
| 2 | Off | 24 GB | 82 GB |
| 2 | On | 15 GB | 41 GB |
| 4 | On | 10 GB | 25 GB |
| 8 | On | 6 GB | 20 GB |
| 22 | On | – | 12 GB |
当细化因子 r = 3 和 r = 5 时,在单节点计算机上执行了域分解预处理并启用了 重新计算并清除选项后,迭代求解器的内存占用量。
正如热粘性声学案例所示,“域分解”求解器能够大幅降低仿真的内存需求。借助这一方法,我们便能使用域分解方法来求解计算量很大的复杂问题。此外,在求解大型问题时,基于分布式域处理的并行计算是提高计算效率的重要手段。
更多资源
- 请浏览本系列博客的第一部分:使用 COMSOL Multiphysics® 中的域分解求解器
- 浏览“COMSOL 博客”,阅览更多关于计算穿孔板的声学转移阻抗的信息



评论 (2)
鹏 喻
2018-04-12请问一下,分成的子域数和节点数有什么关系么?
宇航 秦
2018-04-13喻鹏,您好!
有关模型的问题请发送至 support@comsol.com
谢谢。