跟踪参数扫描中的特征模态
在结合参数扫描进行特征频率分析时,模态解不一定总是按模态族排序。当线性系统中存在模态交叉或简并时,这种情况尤为明显。这篇文章,您将学习如何使用 COMSOL Multiphysics® 中的模态重叠积分对特征模态进行分类。
Note: COMSOL Multiphysics 6.4 及以上版本支持 模态跟踪 功能。
一个简单的例子
先来看一个相对简单的例子:一个外部边界固定的椭圆形域上的二维波动方程(位移  )。沿着椭圆高度方向扫描,同时求解前五个特征模态。椭圆的宽度固定为
)。沿着椭圆高度方向扫描,同时求解前五个特征模态。椭圆的宽度固定为  ,高度
,高度  在 8 cm 和 12 cm 之间变化。在此参数范围的中间
在 8 cm 和 12 cm 之间变化。在此参数范围的中间  , 模拟域是一个完美的圆,对称性导致某些特征模态相互简并。前五个模态的位移大小如下。
, 模拟域是一个完美的圆,对称性导致某些特征模态相互简并。前五个模态的位移大小如下。

沿椭圆高度方向扫描时的前五个特征模态。
请注意,在  处,当固有频率与椭圆高度相对应时,会出现模态交叉。
处,当固有频率与椭圆高度相对应时,会出现模态交叉。

二维波动方程的特征频率与椭圆域高度的关系图。注意 b = 10 cm 处的模态交叉。
仔细观察后,我们发现模态 2 和模态 3 在交叉后混在一起了。出现这种情况是因为特征值是根据其在解数据集中的顺序着色的。We can resolve this through either the preferred, automatic approach or through using a more manual implementation。
Automatic Approach: Mode Following
To remedy this using an automated approach, we can use the built-in mode following functionality. You can follow along in the software by opening the starting model file here.
The first step is to navigate to the Eigenfrequency study step in the model. Upon selecting the node in the model tree for the respective study, expand the Filtering and Sorting section in the Settings window. From there you can select the Mode following checkbox, which automatically tracks eigenmodes as they evolve during a parametric sweep.
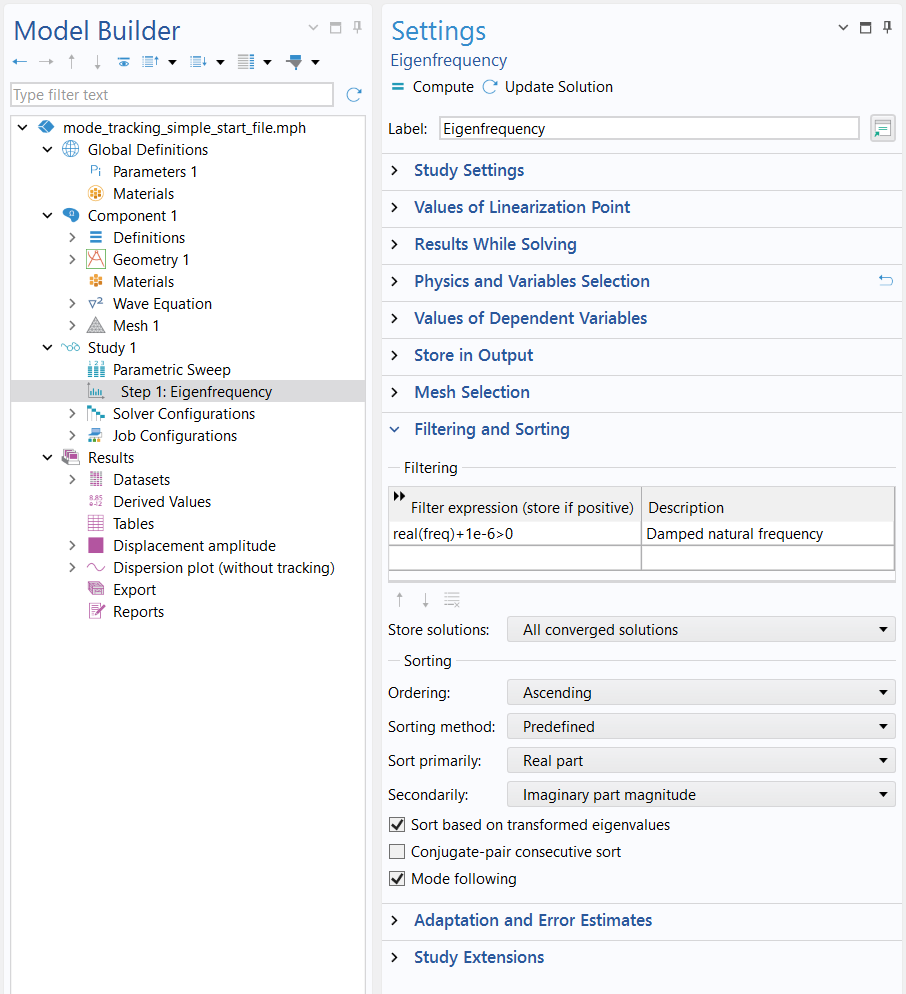
In the Settings window for the Eigenfrequency study, the Mode following checkbox is selected.
Now, recompute the study. Once the model has finished computing the study, the plot will update with the modes tracked.
![]()
Eigenfrequencies of the 2D wave equation plotted against the height of the elliptical domain. The modes are kept track of even with mode-crossing behavior at b = 10 cm.
You can compare the updated plot with tracking to the original plot without tracking by downloading and opening the completed model file, which uses the manual approach of the mode overlap integral, here. You will notice that in the completed model file that the plot with tracking exactly matches the plot you have just generated.
Manual Approach: Mode Overlap Integral
为了解决这个问题,我们可以使用模态重叠积分来对模态解进行分类:

上式的定义最为宽泛, 和
和  代表两个任意的特征模态解。对整个模拟域进行积分,星号表示复共轭。分子表示两种模态之间的内积,而分母则将
代表两个任意的特征模态解。对整个模拟域进行积分,星号表示复共轭。分子表示两种模态之间的内积,而分母则将  的值归一化,使其介于 0 和 1 之间。对于这个特定问题,重叠积分可简化为
的值归一化,使其介于 0 和 1 之间。对于这个特定问题,重叠积分可简化为

在接下来的章节中,我们将演示如何通过重叠积分计算对模态进行分类。您可以点击打开 此处 的模型文件来跟着学习。
定义模态归一化变量
第一步是定义一个模态归一化变量,以便在以后的重叠积分计算中引用。模态归一化的数学定义如下:

首先,创建一个覆盖整个模拟域的积分算子。

积分 节点的设置窗口。
然后,创建一个 变量 节点,并使用以下表达式定义一个 modeNorm 变量:
intop1(u^2)

变量 节点的设置窗口。
请注意,合适的表达式会因模型物理场和因变量的不同而不同。例如,当因变量是电场的分量时,积分应定义电场与其共轭的点积。
定义 modeNorm 变量后,计算研究结果。
使用合并数据集设置参考模态
我们将使用 合并 数据集,以便于比较特定的模态解(也称为参考模态)和完整的模态解。参考模态应是所追踪模态系列中具有代表性的解。
计算研究结果后,右键单击 数据集 并选择合并。

合并 节点的设置窗口。
设置 数据 1 为参考模态。对于本文示例,我们选择  的第一特征模态。设置 数据 2 为完整解。对于组合方法,请选择 显式。显式方法允许我们使用 data1() 和 data2() 算子参考每个解的特定变量。
的第一特征模态。设置 数据 2 为完整解。对于组合方法,请选择 显式。显式方法允许我们使用 data1() 和 data2() 算子参考每个解的特定变量。
使用计算组计算模态重叠
接下来,右键单击 结果 并添加一个计算组。将源数据集设置为 合并 数据集。

计算组 节点的设置窗口。
右键单击新的 计算组 节点,添加 表面积分 子节点(对于三维问题,用 体积分 代替 表面积分)。选择 所有域 ,需要积分的表达式如下:
data1(u)*data2(u)/sqrt(data1(modeNorm)*data2(modeNorm))

表面积分子 节点的设置窗口。
这里,data1(u) 指的是参考模态的位移, data2(u) 指的是其他模态的位移。在分母中,我们参考了之前定义的模态归一化变量。
接下来,修改 计算组 节点设置中的 变换 设置,如下图所示。

计算组节点 变换 设置 的设置窗口。
在表达式框中, int1 表示 表面积分 节点计算的积分值, abs(int1)^2 表示等式 2 中定义的 值。这里的目标是生成一个新的布尔数据列,表示重叠值是否与参考模态匹配(1 表示匹配,0 表示不匹配)。因此,表达式中的 与阈值 0.5 之间存在逻辑比较。
请注意,阈值并不是固定不变的,而是可能因问题而异,或因不同的模态系列而异。我们的目标是选取一个阈值,将属于所需模态系列的解与其他解区分开来。对于模态重叠值分布较广的问题,可能需要通过反复试验进行微调。
在上图所示的 列 标题框中,我们可以选择为变换后的数据列添加标题。还可以选中 保留子节点 选项,以保留原始重叠数据列。完成后,点击 计算 按钮。请注意,计算可能需要一些时间,尤其是对于大型模型。

计算组 表格。
计算完成后,应显示与上表类似的表格。如果希望在表格中添加更多数据列,可以通过在 计算组 中添加额外的计算节点来实现。切记使用 data1() 和 data2() 算子引用相应的模态解。
用表图绘图
创建 一维绘图组 并添加 表图 节点。

表图 节点的设置窗口。
选择新创建的 计算组 作为数据源。选择适当的 X 轴数据(扫描参数)和绘图列(特征值)。可根据需要调整着色、样式和图例选项。
接下来,右键单击 表图 节点,添加一个 过滤器 子节点。在表达式框中输入 col3==1。这里, col3 指的是模态匹配数据列。

过滤器 子节点的设置窗口。
过滤器 子节点根据给定的逻辑标准过滤绘图数据。在这种情况下,只绘制匹配模态解。单击绘图按钮执行绘图。
追踪其他模态系列
要追踪其他模态系列,我们只需重复前面的步骤。您可以使用 复制 操作来快速设置其他 合并、计算组 和 表图 节点。为此,右键单击相应节点并选择 复制(快捷键 CTRL-SHIFT-D)。对于每个新模态系列:
- 复制 加入 数据集。重命名节点并更新数据 1 部分,使其指向新的参考模态。
- 复制 计算组。重命名节点并将源数据集更改为新的 合并 数据集。单击 计算 获取数据表。
- 复制 表图 节点。将计算组来源更改为新的计算组。根据需要更改颜色、样式和图例选项。单击 绘图 更新图表。
您还可以将节点分组,以便更好地组织模型树。为此,请选中所有要分组的节点,右键单击并选择 分组(快捷键 CTRL-G)。

模型开发树显示了模态匹配组。
重要使用说明
- 切记在做出任何会影响模态匹配结果的更改后,重新计算每个 计算组。
- 在清除解或对特征频率研究进行重大修改后,有时需要重新设置 合并 数据集的参考模态。为了提高可重复性,我们建议在外部文件中记录每个 合并 数据集使用的参考模态。
- 关于参考模态的选择,我们建议选择一个与其模态系列中的其他模态重合度较高,而与另外的模态相似度较低的模态。通常,通过绘制模态解可以直观地确定这一点。如果某个模态系列在参数范围内变化很大,则可能需要通过一些尝试才能找到合适的参考模态。
进一步学习
查看这篇 博客文章 了解应用于各种物理应用中的模态追踪演示。要了解更多有关 合并 数据集及其各种其他用途的信息,请参阅这篇 博客文章。
请提交与此页面相关的反馈,或点击此处联系技术支持。