
建模与仿真已成为科学与工程领域的基石,为描述影响设备与工艺运行的物理行为提供了一个框架——从智能手机设计到核电站的控制均涵盖在内。这些物理行为往往都涉及电磁场、流体流动、热传递和机械应力等多种现象。
仿真依赖于对这些效应的数学描述,将它们转化构建为数值模型,进而可以形成庞大的方程组,其中包含的未知量数量与有限元法或边界元法中使用的自由度数(DOF)直接相关。通过求解这些方程能够预测设备与工艺行为,深入理解并优化各类设计——从智能手机中指纹传感器的布局,到发电厂涡轮叶片的形状与性能。
这种理解、预测和优化设计的能力,将原本需要多轮实验测试的过程转化为以计算为主的过程,大幅减少了实验和制作物理原型的次数。然而,将这种计算能力进行更广泛的应用时,必须求解庞大的方程组是一个绕不过去的障碍,因为这通常需要高性能计算机。因此,传统上大多数仿真工作都局限于由研发部门的专业人员来完成。
GPU 加速技术有望改变这一现状。通过大幅缩短求解时间,可以使仿真专家能够及时为组织内各团队和部门提供仿真见解,推动基于物理原理的决策制定。专家们还能通过提供仿真 App,让非专业同事通过直观、简洁的用户界面运行仿真计算,进一步扩大 GPU 加速仿真结果的使用范围。本文,我们将详细阐述基于 GPU 计算的最新进展将如何拓展建模与仿真的应用边界。
GPU 加速为何对多物理场仿真至关重要
多数仿真问题不仅涉及单一物理现象,更包含多种同时相互作用的物理现象。多物理场仿真通过在单一模型中耦合这些交互作用来捕捉这些复杂的交互关系,例如,传热影响流体流动、电磁场与热膨胀及机械应力相互作用、结构振动产生声波等。这些耦合关系对准确呈现真实世界的行为至关重要,但相较于单物理场分析,其计算需求也大幅增加。
随着多物理场模型的规模与复杂度不断增加,涉及数百万及更多自由度、非线性耦合以及随时间变化的行为,基于 CPU 的求解器可能会成为计算瓶颈。这类工作负载需要进行大量的线性代数运算,尤其是在隐式时间步长和非线性求解器迭代过程中需要反复进行矩阵分解。
随着 COMSOL Multiphysics® 软件的最新发展以及 NVIDIA® 提供的 GPU 计算支持,新的解决方案正在形成,物理模型得以更高效地求解,仿真工具也能更深度地嵌入工程与业务流程。在 2025 年 11 月发布的 COMSOL Multiphysics® 6.4 版本中,新增了对 NVIDIA CUDA®直接稀疏求解器(NVIDIA cuDSS)的支持,通过利用 GPU 的大规模并行架构加速计算过程。GPU 通常拥有数千个轻量级处理核心和高内存带宽,使其非常适用于物理仿真中常见的高强度数值计算任务。
当使用 NVIDIA cuDSS 求解器时,GPU 可使仿真速度提升数倍。以声学换能器仿真为例——这类多物理场分析对优化微型耳塞和智能手机扬声器至关重要——GPU 加速求解器相较于纯 CPU 计算展现出显著的加速效果。
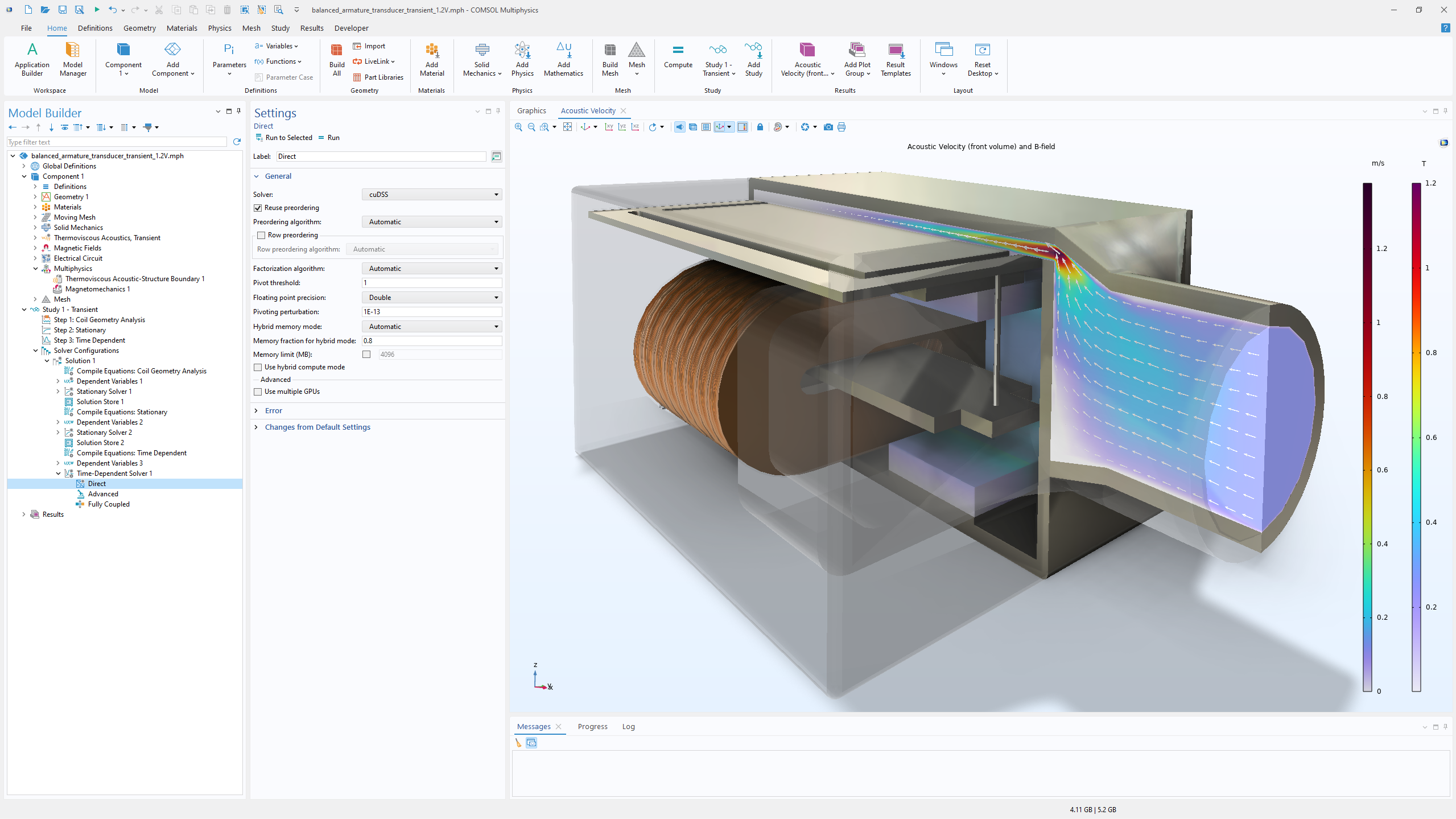 平衡电枢换能器(常见于入耳式音频设备)耦合结构分析、非线性磁学、声学、电路及运动部件,进行时域仿真。当采用基于 NVIDIA H100 GPU 的新 NVIDIA cuDSS 求解器进行计算时,相较于搭载 Intel®酷睿™ i9-10920X 处理器的工作站上运行的 CPU 求解器,速度提升了 8 倍。
平衡电枢换能器(常见于入耳式音频设备)耦合结构分析、非线性磁学、声学、电路及运动部件,进行时域仿真。当采用基于 NVIDIA H100 GPU 的新 NVIDIA cuDSS 求解器进行计算时,相较于搭载 Intel®酷睿™ i9-10920X 处理器的工作站上运行的 CPU 求解器,速度提升了 8 倍。
COMSOL Multiphysics® 中 GPU 支持范围的扩展
在最近的几个版本中,GPU 计算技术逐步整合到了 COMSOL Multiphysics® ,带来了更广泛的功能,并提升了可扩展性。2024 年发布的 6.3 版本引入了基于 GPU 加速的显式压力声学求解,通过定制的 NVIDIA CUDA®算法实现,专为高频和大尺寸域模拟而设计。NVIDIA CUDA-X cuBLAS 库加速了这种 GPU 公式,提升了处理复杂计算任务的性能与效率。该版本还增加了对深度神经网络(DNN)训练的GPU支持,缩短了仿真 App 和数字孪生中数据驱动代理模型的训练时间。在 6.4 版本中,时间显式压力声学功能得到了进一步扩展,可在多卡 GPU 及 GPU 集群上运行。
6.4 版本通过引入 NVIDIA cuDSS 技术,进一步将 GPU 加速扩展至通用多物理场仿真,而且还为采用 NVIDIA cuDSS 的模型新增了多 GPU 支持,用户可在单台计算机上使用多张 GPU 卡并行运行模型。此功能不仅提升了性能,更突破了容量限制:单 GPU 仿真受限于单张显卡的内存容量,而多 GPU 则可以有效地解决此问题,实现大型模型的高效求解。
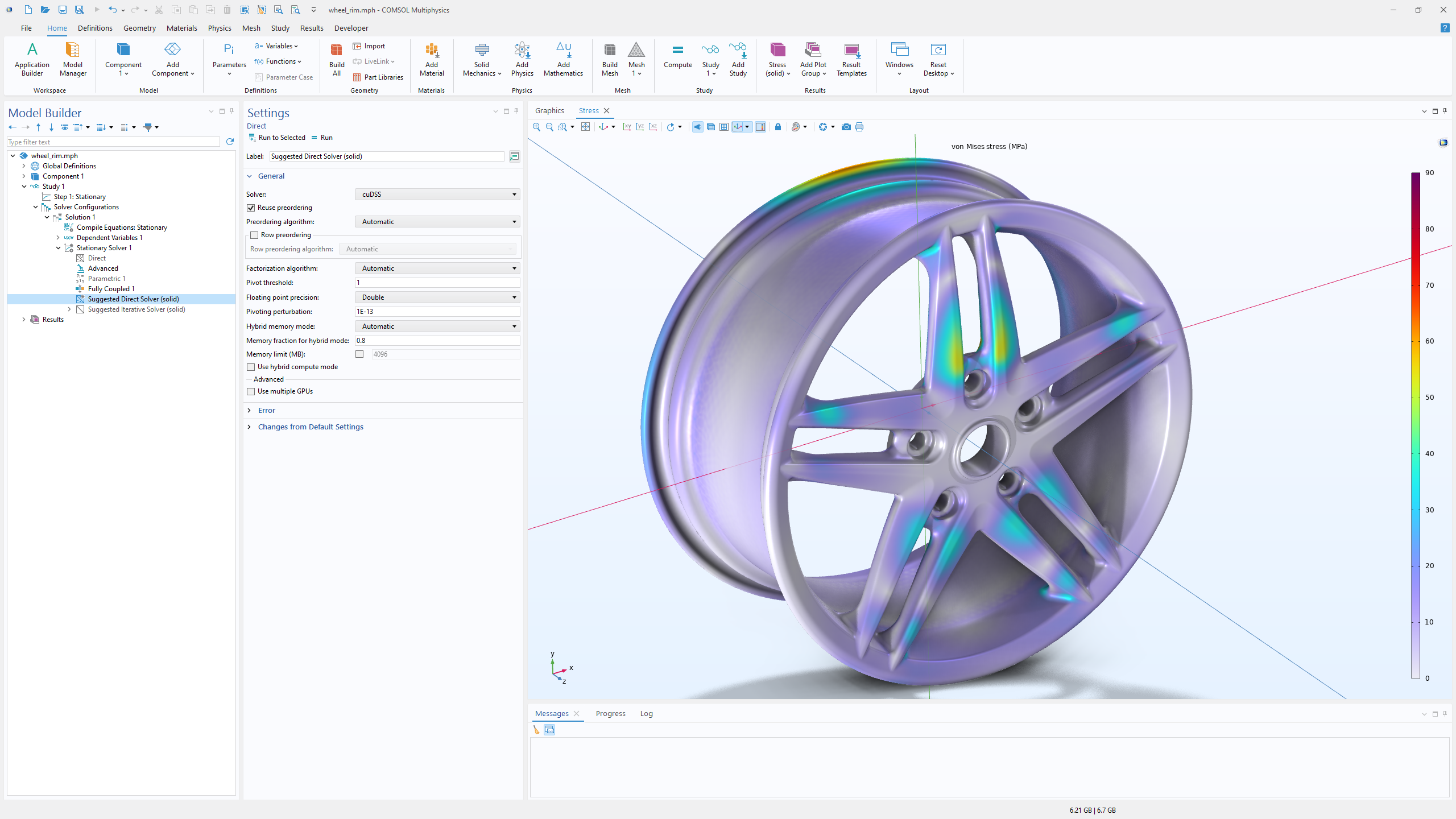 6.4 版本新增的 NVIDIA cuDSS GPU 加速功能,也可在标准工作站硬件上进行常规结构有限元分析。这个显示有效应力结果的轮辋案例,使用 NVIDIA RTX™ 5000 Ada Generation 工作站 GPU 的加速求解,相较于基于 Intel® W5-2465X 处理器的 CPU 求解,速度提升了 2 倍。
6.4 版本新增的 NVIDIA cuDSS GPU 加速功能,也可在标准工作站硬件上进行常规结构有限元分析。这个显示有效应力结果的轮辋案例,使用 NVIDIA RTX™ 5000 Ada Generation 工作站 GPU 的加速求解,相较于基于 Intel® W5-2465X 处理器的 CPU 求解,速度提升了 2 倍。
仿真 App 与代理模型
COMSOL Multiphysics® 最新版本将 GPU 加速引入了仿真 App:用户可通过“App 开发器”基于物理模型开发定制化的用户界面,其中仅需展示几何结构、材料或运行条件等关键参数,使非仿真专家也能使用经过验证的物理模型。
大量仿真 App 直接在底层的高保真模型上运行,借助 GPU 加速的求解器快速输出结果。还有一些 App 可选配深度神经网络(DNN)代理模型——即基于仿真数据训练的简化表示。训练完成后,这些 DNN 代理模型能在数秒内复现原始模型的行为,而 GPU 加速技术使其能够在海量数据集和参数空间中进行训练。
部署这些高度定制化且拥有直观用户界面的 App,能够使交互式仿真能力覆盖整个组织团队:工程师可以实时测试设计方案;制造团队能在车间现场调整工艺参数;运营人员则可通过基于物理原理的数字孪生监控系统运行状态。
对于依赖完整模型或需基于模型进行验证的仿真 App 而言,GPU 加速求解器能显著缩短复杂分析的周转时间。这种加速效果同样适用于通过 COMSOL Compiler™ 编译的仿真 App——该工具可将用户界面与完整的求解器堆栈打包为独立的可执行文件。编译后的仿真App与桌面版 COMSOL® 程序一样可受益于 GPU 加速,使高性能仿真工具无需付费软件许可证即可实现分发。
仿真 App、代理模型、GPU 加速求解器与编译的可执行文件共同提供了一种可扩展的解决方案,将基于物理的分析能力推广至更广泛的用户群体。单个经过验证的模型可演变为一系列可部署的工具,从近乎瞬时的代理模型预测器到 GPU 加速的全保真求解器,所有这些工具都建立在相同的多物理场基础之上。
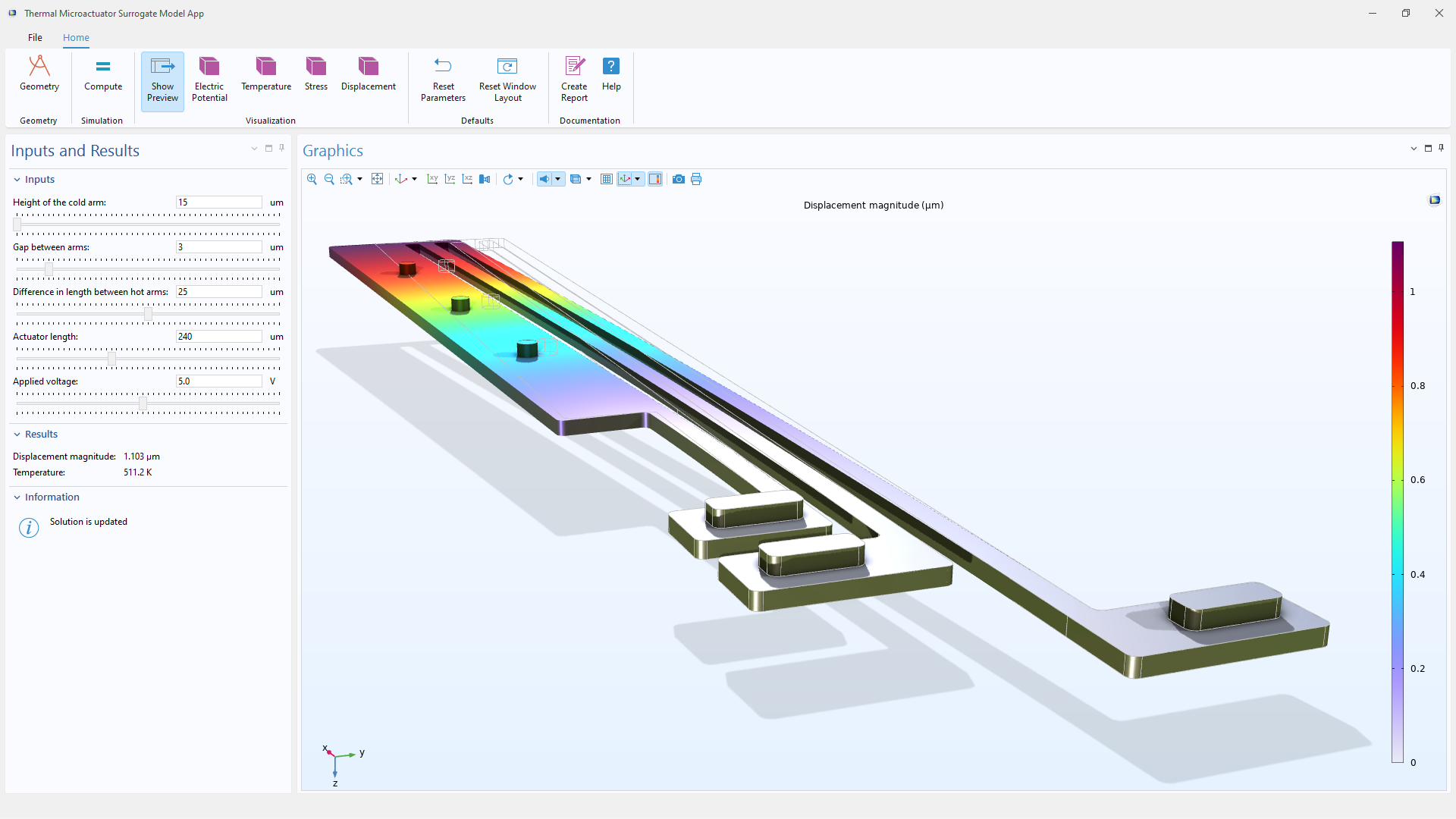 一款基于深度神经网络代理模型的 MEMS 热致动器的仿真 App,能够对温度、位移、电压及应力等参数进行极速的评估。该代理模型在标准工作站上通过 GPU 加速完成训练。
一款基于深度神经网络代理模型的 MEMS 热致动器的仿真 App,能够对温度、位移、电压及应力等参数进行极速的评估。该代理模型在标准工作站上通过 GPU 加速完成训练。
NVIDIA CUDA® 直接稀疏求解器 (NVIDIA cuDSS)
COMSOL Multiphysics® 最新 GPU 加速功能的核心,是适用于NVIDIA GPU 的 NVIDIA CUDA® 直接稀疏求解器(NVIDIA cuDSS),旨在加速多物理场工作流程中计算量最大的步骤之一:反复求解隐式时间步进、非线性分析、参数扫描和特征频率研究中出现的大型稀疏线性方程组。
稀疏直接求解器通常依赖矩阵分解,特别是高度优化且稳健的高斯消元法。这类运算既需要高浮点运算吞吐量,又需要快速的内存访问——而这些恰恰是 GPU 的优势。GPU 提供的海量内存带宽使 NVIDIA cuDSS 能够以远超 CPU 求解器的速度在内存中传输大型稀疏矩阵。这种带宽优势结合数千个并行计算核心,显著缩短了大规模计算工程模型的实际运行时间。
NVIDIA cuDSS 同时支持单精度与双精度运算,其中单精度是否适用取决于模型细节。网格质量、边界条件、材料属性及载荷定义等因素均会影响待求解线性系统的条件数,由于这些因素难以预先评估,因此用户可能需要测试单精度是否能为特定仿真提供稳定准确的结果。
当单精度可行时,性能提升更显著:内存占用减半,浮点运算吞吐量提升,尤其在计算密集型问题或使用低成本 GPU 时(这类 GPU 单精度性能往往优于双精度),可实现大幅加速。对于内存受限的工作负载,受带宽限制影响,性能提升通常接近两倍。但双精度仍然是需要更高数值精度的模拟的合适选择,因此也是在 COMSOL Multiphysics® 中使用 NVIDIA cuDSS 时的默认选项。
由于 NVIDIA cuDSS 可无缝集成至 COMSOL Multiphysics® 的求解器框架中,因此可应用于从线性分析到完全耦合的非线性多物理场模型等广泛的物理模拟。如今,所有直接求解器的应用场景均可采用这项新技术,包括作为迭代求解法中的部分预条件器。
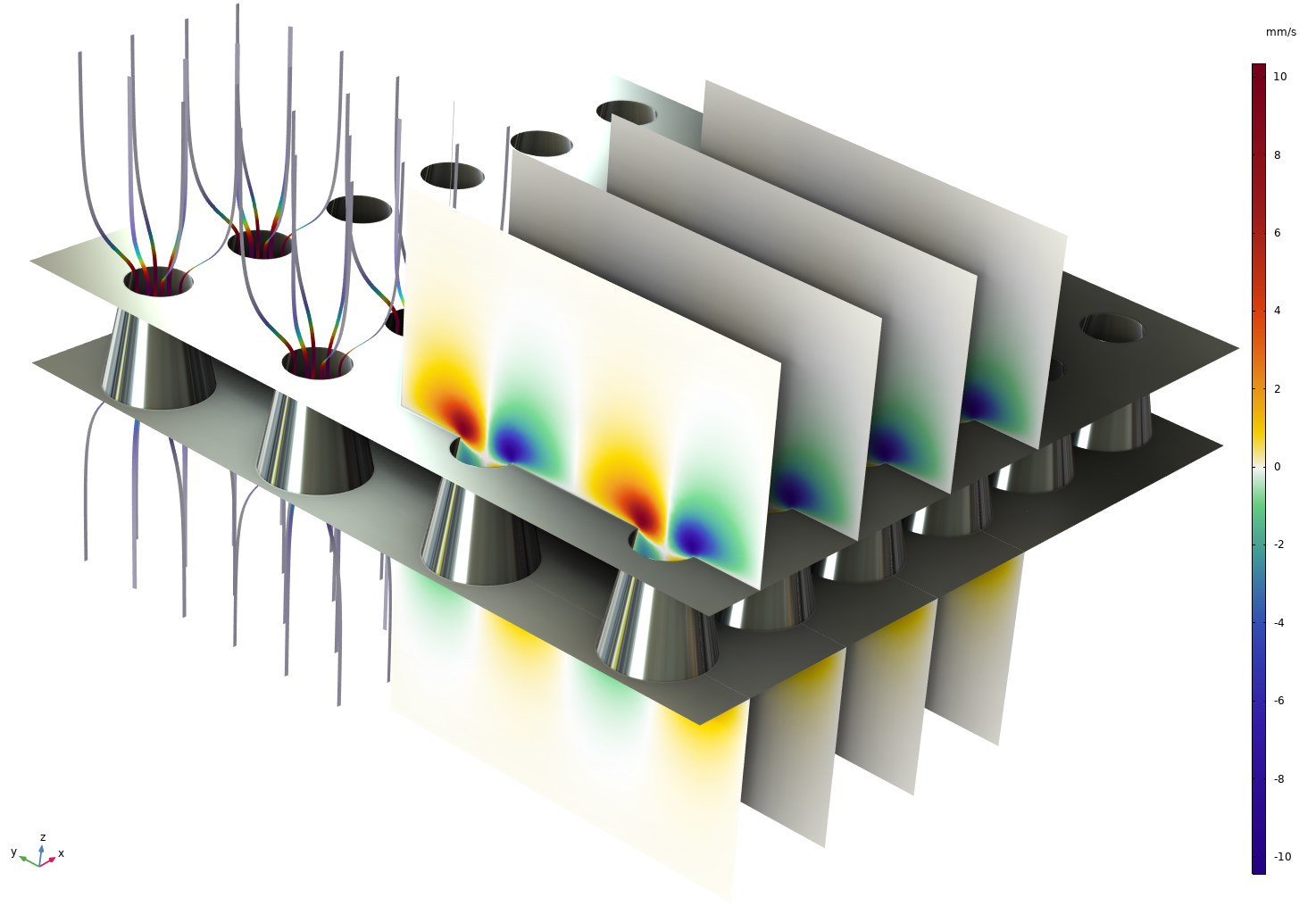
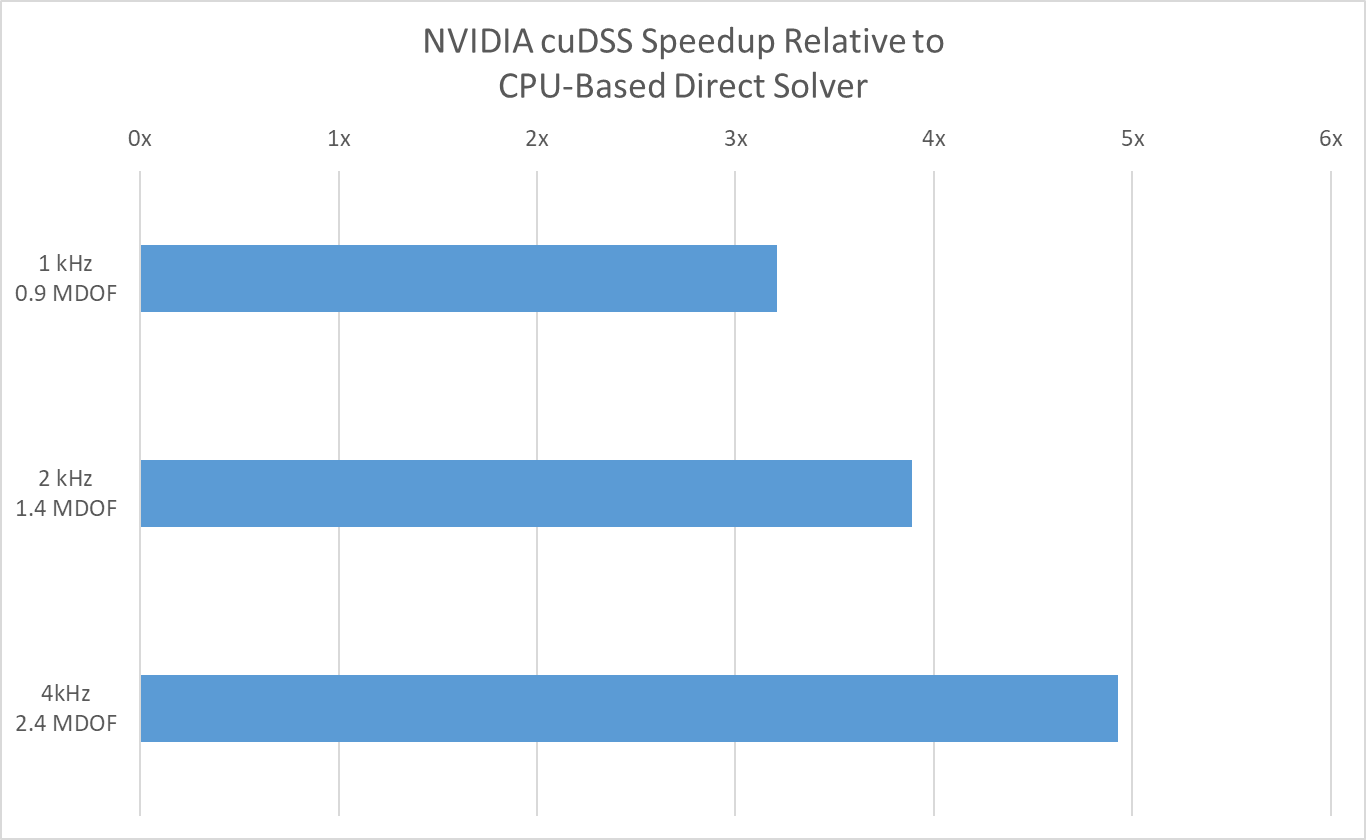
消声器和声衬的穿孔板声学传递阻抗多物理场模型,采用 NVIDIA cuDSS 在四块 NVIDIA H100 GPU 上进行求解。图中显示了声质点速度分布。三个不同规模(90-240 万自由度)的基准测试表明,相较于双核 Intel®至强®铂金 8260 系统上的 CPU 直接求解器,实现了近 5 倍的加速。
推动 GPU 加速仿真的广泛普及
借助 GPU 加速的 NVIDIA cuDSS 求解器,COMSOL Multiphysics® 能够更快地求解大型稀疏矩阵,将原本需要通宵进行的计算任务缩短至数小时内。对于那些需要在参数扫描中运行数千次的小型及中型模型(例如,生成神经网络代理模型的训练数据),同样能获得加速受益。结合仿真 App,这些功能可将完整的物理模型转化为广泛适用的工具集,将先进的多物理场仿真从孤立的专家工作流程转变为日常工程实践。
更进一步
您可以阅读学习中心的文章“用于 COMSOL 计算的 GPU 选择指南”,进一步了解选择用于COMSOL Multiphysics® 的 GPU 时需要考虑的关键因素。点击下方按钮,阅读完整文章。
评论 (2)
晨杰 王
2026-03-10Hello, Dear COMSOLengineer, I would like to ask some questions about the use of GPU and app development in COMSOL6.4:
1. How to use GPU acceleration in COMSOL 6.4, which physics modules can use GPU acceleration, whether the steady-state solver and transient solver can be used, when solving the transient model, which nodes need to use the cudss solver, just open under the “transient solver” node, you can use it. Or do the underlying physics nodes and steady-state solvers also need to be turned on?
2. What is the meaning of the parameter configuration below cudss solver? Is there any relevant help?
3. Is there any case or video related to GPU call and APP development on the official website, preferably the case of using GPU to train the model on the APP? We are very interested in this research
4. Can you build a separate COMSOL artificial intelligence module and give the corresponding use method
Wang Gang
2026-03-13 COMSOL 员工Hi, 1, we have a instructions of setting up GPU in learning center, https://cn.comsol.com/support/learning-center/article/setting-up-gpu-accelerated-computing-within-comsol-multiphysics-92461. A direct solver “cuDSS” can be used for all physics interfaces. And GPU can be used to accelerate Pressure Acoustics, Time Explicit interfaces, and surrogated model trainings. 2, For more details of setting up cuDSS solver, please check the reference manual shipped with installation. 3, Please check the link https://cn.comsol.com/support/learning-center/article/gpu-selection-guidelines-for-comsol-computing-131452. 4, We will transfer the request to development.