
几周前,我们发布了“混合建模”系列的第一篇博客文章,介绍了混合并行计算的含义,以及它是如何提高 COMSOL Multiphysics 运算效率的。今天,我们将简要探讨混合并行计算的一个组成部分——共享内存计算。不过在此之前,我们首先会解释“应用程序并行运行”的意义。此外,我们还将讨论何时以及如何在 COMSOL 软件中使用共享内存。
多核和多线程
人们对计算机运算速度的需求日益增长,然而由于一些技术限制(例如时钟频率的提升瓶颈)的存在,迫使计算机进入了多核 时代。如今,多核计算机已经成为主流,市面上常见的处理器通常最多是 12 核,而实际上处理器可以安装多达 60 个以上的核心。如果您希望了解什么是核心,以及它与共享内存计算之间的关联,请查看链接中介绍共享内存计算的图表。
鉴于上述情况,每个应用程序都需要考虑并行性,以有效发挥前沿并行硬件的性能;否则,这些程序只能使用一个 内核执行运算。虽然用户往往不能直接感受并行性的影响,不过,您应当知道自己的计算机拥有并行处理能力,清楚修改哪些软件设置能提高计算效率,明白当所有核心超频时应该做何预期。
如果要使执行一个进程 的应用程序 在一台多核机器上并行运行,必须将它分割成更小的单元,这些单元被称作线程。实现多个线程并发执行的技术叫做多线程。多线程技术在十五年前便已经成为了计算机的内置功能。对于多线程技术而言,多核心并非不可或缺的配置;单核处理器可以采用时间分片模式,通过在活动线程之间快速切换来支持多线程。让一个核心“同时”处理多个线程 有效提高了资源利用率,当然,这一技术也可以应用于多核处理器。
了解基本原理后,我们就很容易理解,为什么说与单核处理器相比,多核处理器向前迈出了一大步。装配多个计算单元便意味着系统可以同时运行多个线程,进而增加了单位时间内的计算量。基于上述原因,并行计算目前是加速计算的主要来源。
下图展示了 COMSOL Multiphysics 与八核处理器相结合的优势。当八个核心都投入应用时,计算时间会大大减少。它带来的直接好处是,在相同时间内可执行的仿真次数大大增加,从而提高了生产率。下图显示了对选定模型进行测试时,八核处理器的生产率是单核处理器的 6.5 倍。
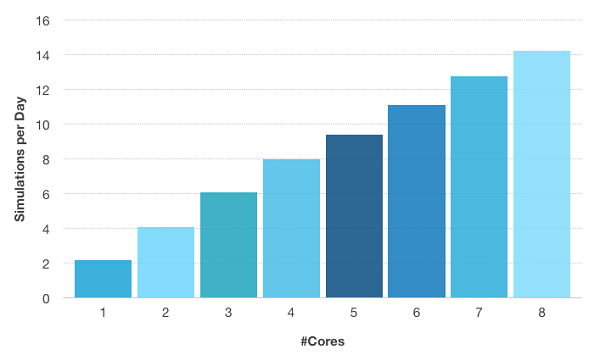
测试下方的射频加热模型时,每日可执行的仿真次数与核心数量之间的关系。用于测试的计算服务器装有 2 个 Intel® Xeon® E5-2609 和 64 GB DDR3 @1600 MHz。
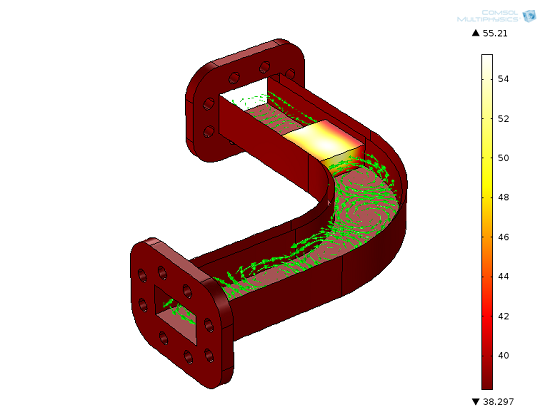
用于测试加速比的模型。右侧的红白渐进标度表示温度(摄氏度),绿色箭头表示磁场。此模型拥有近 140 万个自由度,使用 PARDISO 直接求解器进行求解,并且需要 52 GB 的内存。请注意:这是一个双向耦合的多物理场模型。“案例库”中提供了一款规模相对较小的模型。
什么是共享内存?
当计算机执行一项进程时,操作系统会分配给应用程序一定的内存供其使用(注意:在 COMSOL Multiphysics 中,您可以在底部的工具栏中查看分配给程序的内存大小)。概括而言,由主进程创建的全部线程共享了这些内存,每个线程都可以访问储存在内存中的全部变量。
打个比方,您可以想像一群人围坐在会议室的圆桌旁开会,桌子上摊着所有的重要会议报告和信息。每个参会者可以阅读任何文件,或在上面写字。这样一来,每个参会者都可以挑选自己要处理的文件,所有信息都是共享的。
上述比喻让我们对运行原理有了一个大致印象,因此很大程度上简化了共享内存的概念。毕竟在计算机上进行共享内存编程时,人们必须注意许多方面和细节。很显然,系统需要引入某种同步机制,而且或许会发生资源冲突——毕竟想象一下 50 个人在一张纸上书写时的情景。这也初步解释了为什么第一张图中的加速比逐渐降低并最终将在某一点处达到饱和。
内存共享允许线程直接访问共享的变量,而且程序不必进行通信,也能在线程之间交换信息。在计算中,通信很可能是一个巨大瓶颈,应当尽可能避免;而 COMSOL 软件采用了共享内存,因此在这一方面具有比较优势。当然,共享内存计算也有自己的缺点。正如上一篇系列博客所述,我们可用的内存大小受到计算机内存容量的限制,而且在编写应用程序时,程序员必须考虑到其他逻辑问题。
为什么使用共享内存?
如上所述,并行运算目前是加快计算速度的主要方式。为此,程序员需要清楚如何将整体工作分配给所有参与的线程。不过如果一项任务无需任何依赖项也能并行执行,分配的过程将相当简洁明了。
在数值线性代数中,您常常会同矩阵和矢量等特大型阵列打交道。在这些情况中,最常见的构造是处理阵列的长循环。如果采用共享内存的机制,所有线程都可以访问整个阵列,而且能够通过多种方式将循环拆分给多个线程(前提是不存在循环体依赖)。当 COMSOL Multiphysics 执行各种线性代数运算和特定算法时,都利用了共享内存式并行计算,充分体现了它是一款灵活的并行工具。
但是,对于某些任务和算法,人们很难甚至不可能采用并行计算的方法。斐波那契数列 F(n) = F(n-1) + F(n-2) 就是一个例子,因为其中每个步骤都依赖于上一步,因此它是一个无法采用并行处理的递归问题。其他与并行计算和多核计算机不相容的算法包括时间步进法、延拓(例如递增)研究,它们的共同特征是计算量级不变。
然而,没有人会仅仅为了整日计算斐波那契数列的元素才使用计算机和数值软件;而且幸运的是,市面上每一款有限元分析软件的主要功能——求解线性方程组在很大程度上是可并行的。因此,即使矩阵方程只是某个大型任务(例如瞬态问题)的其中一部分,但是涉及到矩阵求解的问题或多或少都能从多核处理器中受益。对于绝大多数模型而言,COMSOL Multiphysics 主要执行矩阵矢量运算,因此采用共享内存多核处理器具有巨大的优势。对于时间步进算法和延拓研究而言,每个时间步和参数步本身都可以实现并行执行。为了提升这类研究的可扩展性,采用时间步进法或延拓研究的底层物理场应当拥有数量巨大且充足的自由度。
此外,您必须牢记:整体的加速比会受到算法中非并行化分支及其执行情况的限制。阿姆达尔定律描述了这个著名的观察结果。通过推算上述模型中不可并行化的部分,我们发现即使处理器的核心数量可以无限增加,加速比也不会超过 30 倍(不过 30 倍已经相当厉害了!)。因此从理论上讲,COMSOL Multiphysics 每日仿真次数可略高于 60 次。
COMSOL Multiphysics 如何发挥多核配置的优势
当然,只有当多核计算机的所有核心均处于工作状态时,才能获得最优数值仿真性能。COMSOL 软件会默认利用系统中的所有可用核心,因此您无需进行任何特别设置,就能最大限度地利用系统资源。
不过有时您或许需要测量模型或系统的加速比,或者保留几个核心来处理其他应用程序或任务。在这种情况下,您可以更改启动 COMSOL Multiphysics 时默认使用的核心数量,或者在“首选项”设置中编辑“多核与集群计算”。此外,在混合并行计算中,如果同时使用分布式内存和共享内存,利用特定设置可能会取得更佳的效果。
我们将在下一篇系列博客文章中继续探讨这一主题,敬请期待!
扩展阅读
- 正如第一篇系列博客提到的,如果您希望研读共享内存计算的背景知识,劳伦斯利弗莫尔国家实验室(Lawrence Livermore National Laboratory)的《并行计算导论》非常值得一读。
- 请将“混合建模”系列加入收藏,以免错过新文章。

评论 (0)